Unity网络开发基础——消息处理(伍)
学习笔记主要来源于唐老狮的Unity课程,经过个人简单整理而成。笔记总共五个部分:
- Unity网络开发基础——基础知识(壹)
- Unity网络开发基础——TCP与UDP(贰)
- Unity网络开发基础——FTP(叁)
- Unity网络开发基础——HTTP(肆)
- Unity网络开发基础——消息处理(伍)
这个课程的大致内容如下:
- 网络通信中的一些必备理论知识(OSI模型、TCP/IP协议等)。
- 对自定义类对象进行序列化和反序列化。
- 使用Socket,进行TCP、UDP的同步异步通信。
- 处理网络通信中的分包黏包和心跳消息。
- 使用FTP和HTTP协议进行文件的上传和下载。
- 掌握Unity的WWW类和UnityWebRequest类。
- 熟练使用Protobuf,了解自定义协议生成工具的制作原理。
- 了解大小端模式,消息加密原理。
课程不包含游戏的实际游戏开发的内容,比如后端相关知识、同步模式(帧同步、状态同步)等等,只包含网络通信最基本的内容。
八、消息处理
(一)协议生成工具概述
1、概述
协议(消息)生成工具,就是专门用于自动化生成消息的程序。在介绍之前,我们先回顾之前学习的内容:
- 在【第三章:网络通信前置知识,第六小节:序列化和反序列化实践】中,我们制作了BaseData,知道了如何序列化和反序列化对象。
- 在【第四章:网络通信Socket——TCP,第二小节:UDP通信——同步】中,我们制作了BaseMessage,知道了消息的序列化和反序列化,区分消息类型,以及分包黏包处理。
当处理新消息时,我们需要手动声明一个新的类,继承BaseMessage并且手动实现相关方法。而这部分做了几遍你会发现很多工作都是重复的。同时,如果前后端语言不统一,前后端分开声明,容易造成不一致的问题。
因此我们需要一个协议生成工具,能够帮助我们自动生成消息类或数据类的代码,这不仅能够提高开发效率,而且能够降低沟通成本,避免前后端消息不匹配的问题。
2、如何制作协议生成工具
制作工具前都需要先明确需求,对于协议生成工具,我们的需求如下:
- 通过配置文件配置消息或数据类的名字、变量等。
- 工具根据配置文件信息动态的生成类文件。
- 开发时就可以直接使用这些类文件,提高开发效率。
那么,我们制作的步骤如下:
- 确定协议配置方式:可以使用
json、xml、自定义格式等进行协议配置,根据自己喜好而定,这里选择xml。 - 确定生成格式:最终会生成类文件,而我们需要提取出这些类在声明时的共同点和固定写法,明确生成的格式。
- 制作生成工具:在Unity编辑器中制作一个工具,最终成果是可以基于配置文件和生成格式动态生成对应类文件。
(二)协议生成工具制作
1、配置规则
配置规则需要自己制定,这里需要配置枚举、数据结构类、消息类三种,配置规则如下:
- 枚举类型配置
<enum name="枚举名" namespace="命名空间">
<field name="字段名">枚举值</field>
<!-- 其他字段...... -->
</enum>
- 数据结构类配置
这里自己制定了列表、字典等数据如何配置,解析时按照这个规则解析即可。
<data name="数据结构类名" namespace="命名空间">
<field type="数据类型" name="数据名">默认值</field>
<field type="array/list" elementType="元素类型" name="数据名">默认值</field>
<field type="dictionary" keyType="键类型" valueType="值类型" name="数据名">默认值</field>
<field type="enum" enumType="枚举类型" name="枚举名"/>
<!-- 其他字段...... -->
</data>
- 消息类配置
和数据结构类不同的是,消息需要一个消息ID,因此多一个ID属性,此外字段的配置还是不变。
<message id="消息ID" name="消息类名" namespace="命名空间">
<field type="数据类型" name="数据名">默认值</field>
<!-- 其他字段...... -->
</message>
2、准备配置文件
这里我们准备一个xml配置文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<messages>
<!-- 枚举配置 -->
<!-- 玩家枚举 -->
<enum name="E_PlayerType" namespace="GamePlayer">
<field name="Main">0</field>
<field name="Other"/>
</enum>
<!-- 数据结构类配置 -->
<!-- 玩家数据 -->
<data name="PlayerData" namespace="GamePlayer">
<field type="int" name="id"/>
<field type="float" name="hp"/>
<field type="long" name="lev"/>
<field type="array" elementType="int" name="equipIds"/>
<field type="list" elementType="int" name="skillList"/>
<field type="dictionary" keyType="int" valueType="string" name="itemDict"/>
<field type="enum" enumType="E_PlayerType" name="playerType"/>
</data>
<!-- 消息类配置 -->
<!-- 玩家消息 -->
<message id="1001" name="PlayerMessage" namespace="GamePlayer">
<field type="int" name="PlayerID"/>
<field type="PlayerData" name="data"/>
</message>
<!-- 心跳消息 -->
<message id="1002" name="HeartMessage" namespace="GameSystem"/>
</messages>
3、解析配置并生成文件
接下来需要解析配置的内容,这里需要用到XML的知识,在Unity数据持久化中已经有提及,这里不再赘述。解析XML后就是生成对应的类文件,这里将其制作成一个编辑器工具。
这里准备两个类:
- ProtocolTool:协议生成工具,用于在Unity编辑器的工具栏中提供一个按钮,点击即可根据配置文件生成类文件。
- GenerateCSharp:生成C#脚本的辅助类,由ProtocolTool调用,后续如果需要制作类似C++、Java的类都可以像这样拓展。
(1)ProtocolTool类
该类的代码如下:
- 成员变量定义了配置文件路径。
GenerateCSharp方法用于根据配置文件生成C#脚本,分别调用了里面的三个对应方法。GetNodes方法用于解析Xml文件,提取出里面的所有指定节点,如之前定好规则的三个节点:enum、data、message。
public class ProtocolTool
{
// 配置文件路径
private static string PROTOCOL_INFO_PATH = Application.dataPath + "/Editor/ProtocolTool/ProtocolInfo.xml";
// 用于生成C#脚本的辅助类对象
private static GenerateCSharp generateCSharp = new GenerateCSharp();
[MenuItem("ProtocolTool/生成C#脚本")]
private static void GenerateCSharp()
{
// 生成枚举脚本
generateCSharp.GenerateEnum(GetNodes("enum"));
// 生成数据结构类脚本
generateCSharp.GenerateData(GetNodes("data"));
// 生成消息类脚本
generateCSharp.GenerateMessage(GetNodes("message"));
// 刷新
AssetDatabase.Refresh();
}
/// <summary>
/// 获取所有指定xml节点
/// </summary>
/// <param name="nodeName">节点名</param>
/// <returns>xml节点列表</returns>
private static XmlNodeList GetNodes(string nodeName)
{
// 加载XML文件
XmlDocument xml = new XmlDocument();
xml.Load(PROTOCOL_INFO_PATH);
// 获取根节点
XmlNode root = xml.SelectSingleNode("messages");
// 返回所有指定节点
return root.SelectNodes(nodeName);
}
}
(2)GenerateCSharp类
这个代码有点多,但是其实核心思路就是掌握每个类的套路写法,根据配置文件读取的内容转成字符串,然后将字符串写入文件中。当然这个代码还是有很多可以优化的地方的,比如字符串拼接可以使用原始字符串字面量"""让其更加易读,再比如可以支持更多变量类型,给生成的代码添加注释等等。
每个人的配置规则不同,类声明也不同,但步骤无非就是解析配置规则,然后转成对应字符串写入文件,因此这里主要了解核心思想即可。不过由于代码比较多,因此这里会简单讲解一下。
- 公共方法:供外部调用的生成脚本的方法。
- GenerateEnum:生成枚举类脚本。这个比较简单,只需要拼接所有字段名就行,若有枚举值则添加上即可。最终将拼接的字符串写入文件。
- GenerateData:生成数据类脚本。除了生成字段名,由于继承了BaseData,还需要补充3个方法的字符串。这些计算都交由辅助方法完成,后面会提到。这里只负责拼接最终的整个类字符串并写入文件。
- GenerateMessage:生成消息类脚本,和GenerateData类似,但是由于多了消息ID和消息体长度,
Writing方法和GetBytesLength方法需要稍微修改下,以及多了一个GetID方法。拼接好字符串后最终写入文件。
- 私有方法:用于辅助计算不同变量类型的字符串。
- GetFieldStr:获取类所有字段组成的字符串。
- GetBytesLengthStr:获取GetBytesLength方法的字符串。
- GetWritingStr:获取Writing方法的字符串。
- GetReadingStr:获取Reading方法的字符串。
- GetIDStr:获取GetID方法的字符串。
- 关于变量类型:辅助方法的核心计算就是根据不同的变量类型生成不同的字符串文本,这里会简单说明一下不同变量类型的生成规则。
- 基本类型:比较简单,计算字节数组长度时直接获取该类型的字节数组长度即可,读和写都直接调用
WriteXXX和ReadXXX即可。 - String:由于该类型字节数组是不定长的,因此需要记录两样东西:
字节数组长度和字节数组。前者需要int变量记录,后者直接调用Encoding的相关方法获得即可。当然这里读和写已经封装成WriteString和ReadString了。 - Enum:其实就可以转成int类型的数据进行读写,稍微修改下即可。
- BaseData子类:计算字节数组长度时直接调用该对象的
GetBytesLength方法即可,读和写都已经封装成WriteData和ReadData了。 - 数组/List:先记录数组或List的长度,然后遍历数组或List,对每个元素进行计算即可。
- 字典:先记录字典的长度,然后遍历字典,对每个键值对进行计算即可。
- 基本类型:比较简单,计算字节数组长度时直接获取该类型的字节数组长度即可,读和写都直接调用
public class GenerateCSharp
{
// 保存路径
private string SAVE_PATH = Application.dataPath + "/Scripts/Protocol/";
/// <summary>
/// 生成所有枚举脚本
/// </summary>
/// <param name="nodeList">枚举xml节点列表</param>
public void GenerateEnum(XmlNodeList nodeList)
{
foreach (XmlNode enumNode in nodeList)
{
// 命名空间
string namespaceStr = enumNode.Attributes["namespace"].Value;
// 枚举名
string enumNameStr = enumNode.Attributes["name"].Value;
// 所有字段
XmlNodeList fieldNodeList = enumNode.SelectNodes("field");
string fieldStr = "";
foreach (XmlNode fieldNode in fieldNodeList)
{
fieldStr += $"\t\t{fieldNode.Attributes["name"].Value}"; // 枚举名
if (fieldNode.InnerText != "")
fieldStr += $" = {fieldNode.InnerText}"; // 枚举值
fieldStr += ",\r\n";
}
// 拼接字符串
string enumStr = $"namespace {namespaceStr}\r\n" +
"{\r\n" +
$"\tpublic enum {enumNameStr}\r\n" +
"\t{\r\n" +
fieldStr +
"\t}\r\n" +
"}";
// 保存文件
string path = SAVE_PATH + "Enum/";
if (!Directory.Exists(path))
Directory.CreateDirectory(path);
File.WriteAllText(path + enumNameStr + ".cs", enumStr);
}
Debug.Log("枚举文件生成完毕");
}
/// <summary>
/// 生成所有数据结构类脚本
/// </summary>
/// <param name="nodeList">数据结构类节点列表</param>
public void GenerateData(XmlNodeList nodeList)
{
foreach (XmlNode dataNode in nodeList)
{
// 命名空间
string namespaceStr = dataNode.Attributes["namespace"].Value;
// 类名
string classNameStr = dataNode.Attributes["name"].Value;
// 所有字段
XmlNodeList fieldNodeList = dataNode.SelectNodes("field");
string fieldStr = GetFieldStr(fieldNodeList);
// GetBytesLength方法
string getBytesLengthStr = GetBytesLengthStr(fieldNodeList);
// Writing方法
string writingStr = GetWritingStr(fieldNodeList);
// Reading方法
string readingStr = GetReadingStr(fieldNodeList);
// 拼接字符串
string dataStr = "using System;\r\n" +
"using System.Collections.Generic;\r\n" +
"using System.Text;\r\n" +
// 命名空间和类
$"namespace {namespaceStr}\r\n" +
"{\r\n" +
$"\tpublic class {classNameStr} : BaseData\r\n" +
"\t{\r\n" +
// 所有字段
fieldStr +
// GetBytesLength方法
"\t\tpublic override int GetBytesLength()\r\n" +
"\t\t{\r\n" +
"\t\t\tint bytesLength = 0;\r\n" +
getBytesLengthStr +
"\t\t\treturn bytesLength;\r\n" +
"\t\t}\r\n" +
// Writing方法
"\t\tpublic override byte[] Writing()\r\n" +
"\t\t{\r\n" +
"\t\t\tint index = 0;\r\n" +
"\t\t\tbyte[] bytes = new byte[GetBytesLength()];\r\n" +
writingStr +
"\t\t\treturn bytes;\r\n" +
"\t\t}\r\n" +
// Reading方法
"\t\tpublic override int Reading(byte[] bytes, int beginIndex = 0)\r\n" +
"\t\t{\r\n" +
"\t\t\tint index = beginIndex;\r\n" +
readingStr +
"\t\t\treturn index - beginIndex;\r\n" +
"\t\t}\r\n" +
"\t}\r\n" +
"}";
// 保存文件
string path = SAVE_PATH + "Data/";
if (!Directory.Exists(path))
Directory.CreateDirectory(path);
File.WriteAllText(path + classNameStr + ".cs", dataStr);
}
Debug.Log("数据结构类文件生成完毕");
}
/// <summary>
/// 生成所有消息类脚本
/// </summary>
/// <param name="nodeList">消息类节点列表</param>
public void GenerateMessage(XmlNodeList nodeList)
{
foreach (XmlNode dataNode in nodeList)
{
// 命名空间
string namespaceStr = dataNode.Attributes["namespace"].Value;
// 类名
string classNameStr = dataNode.Attributes["name"].Value;
// 所有字段
XmlNodeList fieldNodeList = dataNode.SelectNodes("field");
string fieldStr = GetFieldStr(fieldNodeList);
// GetBytesLength方法
string getBytesLengthStr = GetBytesLengthStr(fieldNodeList);
// Writing方法
string writingStr = GetWritingStr(fieldNodeList);
// Reading方法
string readingStr = GetReadingStr(fieldNodeList);
// GetID方法
string idStr = dataNode.Attributes["id"].Value;
string getIDStr = GetIDStr(idStr);
// 拼接字符串
string dataStr = "using System;\r\n" +
"using System.Collections.Generic;\r\n" +
"using System.Text;\r\n" +
// 命名空间和类
$"namespace {namespaceStr}\r\n" +
"{\r\n" +
$"\tpublic class {classNameStr} : BaseMessage\r\n" +
"\t{\r\n" +
// 所有字段
fieldStr +
// GetBytesLength方法
"\t\tpublic override int GetBytesLength()\r\n" +
"\t\t{\r\n" +
"\t\t\tint bytesLength = 8;\r\n" + // 加上消息ID和消息体长度的8个字节
getBytesLengthStr +
"\t\t\treturn bytesLength;\r\n" +
"\t\t}\r\n" +
// Writing方法
"\t\tpublic override byte[] Writing()\r\n" +
"\t\t{\r\n" +
"\t\t\tint index = 0;\r\n" +
"\t\t\tbyte[] bytes = new byte[GetBytesLength()];\r\n" +
"\t\t\tWriteInt(bytes, GetID(), ref index);\r\n" + // 写入消息ID
"\t\t\tWriteInt(bytes, bytes.Length - 8, ref index);\r\n" + // 写入消息体长度
writingStr +
"\t\t\treturn bytes;\r\n" +
"\t\t}\r\n" +
// Reading方法
"\t\tpublic override int Reading(byte[] bytes, int beginIndex = 0)\r\n" +
"\t\t{\r\n" +
"\t\t\tint index = beginIndex;\r\n" +
readingStr +
"\t\t\treturn index - beginIndex;\r\n" +
"\t\t}\r\n" +
// GetID方法
getIDStr +
"\t}\r\n" +
"}";
// 保存文件
string path = SAVE_PATH + "Message/";
if (!Directory.Exists(path))
Directory.CreateDirectory(path);
File.WriteAllText(path + classNameStr + ".cs", dataStr);
}
Debug.Log("消息类脚本文件生成完毕");
}
/// <summary>
/// 获取所有类字段的字符串
/// </summary>
/// <param name="fieldNodeList">字段节点列表</param>
/// <returns>所有字段组成的字符串</returns>
private string GetFieldStr(XmlNodeList fieldNodeList)
{
string fieldStr = "";
foreach (XmlNode fieldNode in fieldNodeList)
{
// 变量类型
string type = fieldNode.Attributes["type"].Value;
// 变量名
string fieldName = fieldNode.Attributes["name"].Value;
// 拼接
switch (type)
{
case "array":
string arrayElementType = fieldNode.Attributes["elementType"].Value;
fieldStr += $"\t\tpublic {arrayElementType}[] {fieldName};\r\n";
break;
case "list":
string listElementType = fieldNode.Attributes["elementType"].Value;
fieldStr += $"\t\tpublic List<{listElementType}> {fieldName};\r\n";
break;
case "dictionary":
string keyType = fieldNode.Attributes["keyType"].Value;
string valueType = fieldNode.Attributes["valueType"].Value;
fieldStr += $"\t\tpublic Dictionary<{keyType}, {valueType}> {fieldName};\r\n";
break;
case "enum":
string enumType = fieldNode.Attributes["enumType"].Value;
fieldStr += $"\t\tpublic {enumType} {fieldName};\r\n";
break;
default:
fieldStr += $"\t\tpublic {type} {fieldName};\r\n";
break;
}
}
return fieldStr;
}
/// <summary>
/// 获取GetBytesLength方法的字符串
/// </summary>
/// <param name="fieldNodeList">字段节点列表</param>
/// <returns>GetBytesLength方法的字符串</returns>
private string GetBytesLengthStr(XmlNodeList fieldNodeList)
{
// 计算字节数组长度的字符串
string getBytesLengthStr = "";
foreach (XmlNode fieldNode in fieldNodeList)
{
string type = fieldNode.Attributes["type"].Value;
string fieldName = fieldNode.Attributes["name"].Value;
// 根据变量类型的不同,字节数组长度也不同
switch (type)
{
case "array":
string arrayElementType = fieldNode.Attributes["elementType"].Value;
// 数组长度
getBytesLengthStr += $"\t\t\tbytesLength += 4;\r\n";
// 写入每个元素的长度
getBytesLengthStr += $"\t\t\tfor (int i=0; i<{fieldName}.Length; i++)\r\n";
getBytesLengthStr += $"\t\t\t\tbytesLength += {GetFieldBytesLengthStr(arrayElementType, fieldName + "[i]")};\r\n";
break;
case "list":
string listElementType = fieldNode.Attributes["elementType"].Value;
// 列表长度
getBytesLengthStr += $"\t\t\tbytesLength += 4;\r\n";
// 写入每个元素的长度
getBytesLengthStr += $"\t\t\tfor (int i=0; i<{fieldName}.Count; i++)\r\n";
getBytesLengthStr += $"\t\t\t\tbytesLength += {GetFieldBytesLengthStr(listElementType, fieldName + "[i]")};\r\n";
break;
case "dictionary":
string keyType = fieldNode.Attributes["keyType"].Value;
string valueType = fieldNode.Attributes["valueType"].Value;
// 字典长度
getBytesLengthStr += $"\t\t\tbytesLength += 4;\r\n";
// 写入每个元素的长度
getBytesLengthStr += $"\t\t\tforeach ({keyType} key in {fieldName}.Keys)\r\n";
getBytesLengthStr += "\t\t\t{\r\n";
getBytesLengthStr += $"\t\t\t\tbytesLength += {GetFieldBytesLengthStr(keyType, "key")};\r\n"; // 键
getBytesLengthStr += $"\t\t\t\tbytesLength += {GetFieldBytesLengthStr(valueType, fieldName + "[key]")};\r\n"; // 值
getBytesLengthStr += "\t\t\t}\r\n";
break;
default:
getBytesLengthStr += $"\t\t\tbytesLength += {GetFieldBytesLengthStr(type, fieldName)};\r\n";
break;
}
}
return getBytesLengthStr;
}
/// <summary>
/// 获取对应变量类型的字节数组长度的字符串,辅助GetBytesLengthStr方法使用
/// </summary>
/// <param name="type">变量类型</param>
/// <param name="name">变量名</param>
/// <returns>字节数组长度字符串</returns>
private string GetFieldBytesLengthStr(string type, string name)
{
switch (type)
{
case "int":
case "float":
case "enum":
return "4";
case "byte":
case "bool":
return "1";
case "short":
return "2";
case "string":
return $"4 + Encoding.UTF8.GetByteCount({name})";
case "long":
return "8";
default: // 自定义数据结构类(继承BaseData)
return $"{name}.GetBytesLength()";
}
}
/// <summary>
/// 获取Writing方法的字符串
/// </summary>
/// <param name="fieldNodeList">字段节点列表</param>
/// <returns>Writing方法的字符串</returns>
private string GetWritingStr(XmlNodeList fieldNodeList)
{
// 计算中间Writing的字符串内容
string writingStr = "";
foreach (XmlNode fieldNode in fieldNodeList)
{
string type = fieldNode.Attributes["type"].Value;
string fieldName = fieldNode.Attributes["name"].Value;
// 根据变量类型的不同,写入字节数组的方式也不同
switch (type)
{
case "array":
string arrayElementType = fieldNode.Attributes["elementType"].Value;
// 写入数组长度
writingStr += $"\t\t\tWriteInt(bytes, {fieldName}.Length, ref index);\r\n";
// 写入每个元素
writingStr += $"\t\t\tfor (int i=0; i<{fieldName}.Length; i++)\r\n";
writingStr += $"\t\t\t\t{GetFieldWritingStr(arrayElementType, fieldName + "[i]")};\r\n";
break;
case "list":
string listElementType = fieldNode.Attributes["elementType"].Value;
// 写入列表长度
writingStr += $"\t\t\tWriteInt(bytes, {fieldName}.Count, ref index);\r\n";
// 写入每个元素
writingStr += $"\t\t\tfor (int i=0; i<{fieldName}.Count; i++)\r\n";
writingStr += $"\t\t\t\t{GetFieldWritingStr(listElementType, fieldName + "[i]")};\r\n";
break;
case "dictionary":
string keyType = fieldNode.Attributes["keyType"].Value;
string valueType = fieldNode.Attributes["valueType"].Value;
// 写入字典长度
writingStr += $"\t\t\tWriteInt(bytes, {fieldName}.Count, ref index);\r\n";
// 写入每个元素
writingStr += $"\t\t\tforeach ({keyType} key in {fieldName}.Keys)\r\n";
writingStr += "\t\t\t{\r\n";
writingStr += $"\t\t\t\t{GetFieldWritingStr(keyType, "key")};\r\n"; // 键
writingStr += $"\t\t\t\t{GetFieldWritingStr(valueType, fieldName + "[key]")};\r\n"; // 值
writingStr += "\t\t\t}\r\n";
break;
default:
writingStr += $"\t\t\t{GetFieldWritingStr(type, fieldName)};\r\n";
break;
}
}
return writingStr;
}
/// <summary>
/// 获取对应变量类型的Writing字符串,辅助GetWritingStr方法使用
/// </summary>
/// <param name="type">变量类型</param>
/// <param name="name">变量名</param>
/// <returns>变量类型的Writing字符串</returns>
private string GetFieldWritingStr(string type, string name)
{
switch (type)
{
case "byte":
return $"WriteByte(bytes, {name}, ref index)";
case "short":
return $"WriteShort(bytes, {name}, ref index)";
case "int":
return $"WriteInt(bytes, {name}, ref index)";
case "long":
return $"WriteLong(bytes, {name}, ref index)";
case "float":
return $"WriteFloat(bytes, {name}, ref index)";
case "bool":
return $"WriteBool(bytes, {name}, ref index)";
case "string":
return $"WriteString(bytes, {name}, ref index)";
case "enum":
return $"WriteInt(bytes, Convert.ToInt32({name}), ref index)";
default: // 自定义数据结构类(继承BaseData)
return $"WriteData(bytes, {name}, ref index)";
}
}
/// <summary>
/// 获取Reading方法的字符串
/// </summary>
/// <param name="fieldNodeList">字段节点列表</param>
/// <returns>Reading方法的字符串</returns>
private string GetReadingStr(XmlNodeList fieldNodeList)
{
// 计算中间Reading的字符串内容
string readingStr = "";
foreach (XmlNode fieldNode in fieldNodeList)
{
string type = fieldNode.Attributes["type"].Value;
string fieldName = fieldNode.Attributes["name"].Value;
// 根据变量类型的不同,写入字节数组的方式也不同
switch (type)
{
case "array":
string arrayElementType = fieldNode.Attributes["elementType"].Value;
// 获取数组长度
readingStr += $"\t\t\tint {fieldName}Length = ReadInt(bytes, ref index);\r\n";
// 初始化
readingStr += $"\t\t\t{fieldName} = new {arrayElementType}[{fieldName}Length];\r\n";
// 读取每个元素
readingStr += $"\t\t\tfor (int i=0; i<{fieldName}Length; i++)\r\n";
readingStr += $"\t\t\t\t{fieldName}[i] = {GetFieldReadingStr(arrayElementType)};\r\n";
break;
case "list":
string listElementType = fieldNode.Attributes["elementType"].Value;
// 初始化
readingStr += $"\t\t\t{fieldName} = new List<{listElementType}>();\r\n";
// 获取列表长度
readingStr += $"\t\t\tint {fieldName}Count = ReadInt(bytes, ref index);\r\n";
// 读取每个元素
readingStr += $"\t\t\tfor (int i=0; i<{fieldName}Count; i++)\r\n";
readingStr += $"\t\t\t\t{fieldName}.Add({GetFieldReadingStr(listElementType)});\r\n";
break;
case "dictionary":
string keyType = fieldNode.Attributes["keyType"].Value;
string valueType = fieldNode.Attributes["valueType"].Value;
// 初始化
readingStr += $"\t\t\t{fieldName} = new Dictionary<{keyType}, {valueType}>();\r\n";
// 获取字典长度
readingStr += $"\t\t\tint {fieldName}Count = ReadInt(bytes, ref index);\r\n";
// 读取每个元素
readingStr += $"\t\t\tfor (int i=0; i<{fieldName}Count; i++)\r\n";
readingStr += $"\t\t\t\t{fieldName}.Add({GetFieldReadingStr(keyType)}, {GetFieldReadingStr(valueType)});\r\n";
break;
case "enum":
string enumType = fieldNode.Attributes["enumType"].Value;
readingStr += $"\t\t\t{fieldName} = ({enumType}){GetFieldReadingStr(type)};\r\n";
break;
default:
readingStr += $"\t\t\t{fieldName} = {GetFieldReadingStr(type)};\r\n";
break;
}
}
return readingStr;
}
/// <summary>
/// 获取对应变量类型的Reading字符串,辅助GetReadingStr方法使用
/// </summary>
/// <param name="type">变量类型</param>
/// <returns>变量类型的Reading字符串</returns>
private string GetFieldReadingStr(string type)
{
switch (type)
{
case "byte":
return "ReadByte(bytes, ref index)";
case "short":
return "ReadShort(bytes, ref index)";
case "enum":
case "int":
return "ReadInt(bytes, ref index)";
case "long":
return "ReadLong(bytes, ref index)";
case "float":
return "ReadFloat(bytes, ref index)";
case "bool":
return "ReadBool(bytes, ref index)";
case "string":
return "ReadString(bytes, ref index)";
default: // 自定义数据结构类(继承BaseData)
return $"ReadData<{type}>(bytes, ref index)";
}
}
/// <summary>
/// 获取GetID方法的字符串
/// </summary>
/// <param name="id">ID</param>
/// <returns>GetID方法的字符串</returns>
private string GetIDStr(string id)
{
return "\t\tpublic override int GetID()\r\n" +
"\t\t{\r\n" +
$"\t\t\treturn {id};\r\n" +
"\t\t}\r\n";
}
}
4、生成结果
为了方便理解代码,这里贴出最终的生成文件,并手动加上了一些注释。
- 枚举E_PlayerType
namespace GamePlayer
{
public enum E_PlayerType
{
Main = 0,
Other,
}
}
- 数据结构类PlayerData
using System;
using System.Collections.Generic;
using System.Text;
namespace GamePlayer
{
public class PlayerData : BaseData
{
public int id;
public float hp;
public long lev;
public int[] equipIds;
public List<int> skillList;
public Dictionary<int, string> itemDict;
public E_PlayerType playerType;
public override int GetBytesLength()
{
int bytesLength = 0;
// id:int
bytesLength += 4;
// hp:float
bytesLength += 4;
// lev:long
bytesLength += 8;
// 数组
bytesLength += 4; // 数组长度
for (int i=0; i<equipIds.Length; i++)
bytesLength += 4;
// 列表
bytesLength += 4; // 列表长度
for (int i=0; i<skillList.Count; i++)
bytesLength += 4;
// 字典
bytesLength += 4; // 字典长度
foreach (int key in itemDict.Keys)
{
bytesLength += 4; // key:int
bytesLength += 4 + Encoding.UTF8.GetByteCount(itemDict[key]); // value:string
}
// 枚举
bytesLength += 4;
return bytesLength;
}
public override byte[] Writing()
{
int index = 0;
byte[] bytes = new byte[GetBytesLength()];
// id
WriteInt(bytes, id, ref index);
// hp
WriteFloat(bytes, hp, ref index);
// lev
WriteLong(bytes, lev, ref index);
// 数组
WriteInt(bytes, equipIds.Length, ref index);
for (int i=0; i<equipIds.Length; i++)
WriteInt(bytes, equipIds[i], ref index);
// 列表
WriteInt(bytes, skillList.Count, ref index);
for (int i=0; i<skillList.Count; i++)
WriteInt(bytes, skillList[i], ref index);
// 字典
WriteInt(bytes, itemDict.Count, ref index);
foreach (int key in itemDict.Keys)
{
WriteInt(bytes, key, ref index);
WriteString(bytes, itemDict[key], ref index);
}
// 枚举
WriteInt(bytes, Convert.ToInt32(playerType), ref index);
return bytes;
}
public override int Reading(byte[] bytes, int beginIndex = 0)
{
int index = beginIndex;
// id
id = ReadInt(bytes, ref index);
// hp
hp = ReadFloat(bytes, ref index);
// lev
lev = ReadLong(bytes, ref index);
// 数组
int equipIdsLength = ReadInt(bytes, ref index);
equipIds = new int[equipIdsLength];
for (int i=0; i<equipIdsLength; i++)
equipIds[i] = ReadInt(bytes, ref index);
// 列表
skillList = new List<int>();
int skillListCount = ReadInt(bytes, ref index);
for (int i=0; i<skillListCount; i++)
skillList.Add(ReadInt(bytes, ref index));
// 字典
itemDict = new Dictionary<int, string>();
int itemDictCount = ReadInt(bytes, ref index);
for (int i=0; i<itemDictCount; i++)
itemDict.Add(ReadInt(bytes, ref index), ReadString(bytes, ref index));
// 枚举
playerType = (E_PlayerType)ReadInt(bytes, ref index);
return index - beginIndex;
}
}
}
- 消息类PlayerMessage
using System;
using System.Collections.Generic;
using System.Text;
namespace GamePlayer
{
public class PlayerMessage : BaseMessage
{
public int PlayerID;
public PlayerData data;
public override int GetBytesLength()
{
int bytesLength = 8; // 消息头长度
bytesLength += 4; // playerID:int
bytesLength += data.GetBytesLength(); // data:PlayerData
return bytesLength;
}
public override byte[] Writing()
{
int index = 0;
byte[] bytes = new byte[GetBytesLength()];
WriteInt(bytes, GetID(), ref index); // 消息ID
WriteInt(bytes, bytes.Length - 8, ref index); // 消息体长度
WriteInt(bytes, PlayerID, ref index); // playerID
WriteData(bytes, data, ref index); // data
return bytes;
}
public override int Reading(byte[] bytes, int beginIndex = 0)
{
int index = beginIndex;
PlayerID = ReadInt(bytes, ref index); // playerID
data = ReadData<PlayerData>(bytes, ref index); // data
return index - beginIndex;
}
public override int GetID()
{
return 1001;
}
}
}
- 消息类HeartMessage
using System;
using System.Collections.Generic;
using System.Text;
namespace GameSystem
{
public class HeartMessage : BaseMessage
{
public override int GetBytesLength()
{
int bytesLength = 8; // 消息头长度
return bytesLength;
}
public override byte[] Writing()
{
int index = 0;
byte[] bytes = new byte[GetBytesLength()];
WriteInt(bytes, GetID(), ref index); // 消息ID
WriteInt(bytes, bytes.Length - 8, ref index); // 消息体长度
return bytes;
}
public override int Reading(byte[] bytes, int beginIndex = 0)
{
int index = beginIndex;
return index - beginIndex;
}
public override int GetID()
{
return 1002;
}
}
}
(三)第三方协议工具Protobuf
1、概述
Protobuf全称protocol-buffers(协议缓冲区),是谷歌提供给开发者的一个开源的协议生成工具,它的主要工作原理和我们之前做的自定义协议工具类似,不过它更加的完善,可以基于协议配置文件生成多种语言的代码文件。
它是商业游戏开发中常常会选择的协议生成工具,因为它通用性强,稳定性高,不必自己开发协议工具。
官方网址:Protocol Buffers Documentation
2、使用
(1)使用流程
- 下载Protobuf相关内容。
- 根据配置规则编辑协议配置文件。
- 使用Protobuf编译器,根据协议配置文件生成对应语言的代码文件。
- 将代码文件导入工程中进行使用。
(2)准备DLL文件
- 在Github发布页中下载源代码,比如我目前的是
protobuf-35.0.zip,之后解压。 - 点开如下文件夹:
csharp\src,之后点击Google.Protobuf.sln打开工程。 - 选择
Google.Protobuf项目,右键点击生成,即可生成dll文件。 - 之后在
csharp\src\Google.Protobuf\bin\Debug即可看到各个版本的dll文件,我们选择net45文件夹下的,把里面的所有dll文件复制并放到Unity的Plugins文件夹中。
(3)准备编译器
- 在Github发布页中下载编译器,比如我目前的是
protoc-35.0-win64.zip,之后解压。 - 在
bin目录下,有一个protoc.exe,就是我们的编译器。 - 将其复制并放置到Unity工程中,位置随意,只需要记住它的路径即可。比如我们就在与
Assets同级的位置创建新的文件夹Protobuf,然后将exe放进去。
3、Protobuf配置规则
之前我们使用了xml进行文件的配置,Protobuf原理也是类似的,不过使用的是它自定义的配置文件格式,以.proto作为后缀。
配置规则可以查阅官方文档:Language Guide (proto 3)
- 注释
// 单行注释
/* 多行注释 */
- 版本号
- 第一行声明,不写默认为proto2。
syntax = "proto3";
- 命名空间(包)
package name;
- 定义消息类
- 使用message定义一个消息类。
- 字段声明规则:
类型 字段名 = 编号;,需要注意的是=号右边的不是字段的默认值,而是唯一编号。 - 唯一编号可以保证消息格式在版本演化过程中的前后兼容性,如果字段添加或删除,不会导致解析失败。
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 results_per_page = 3;
}
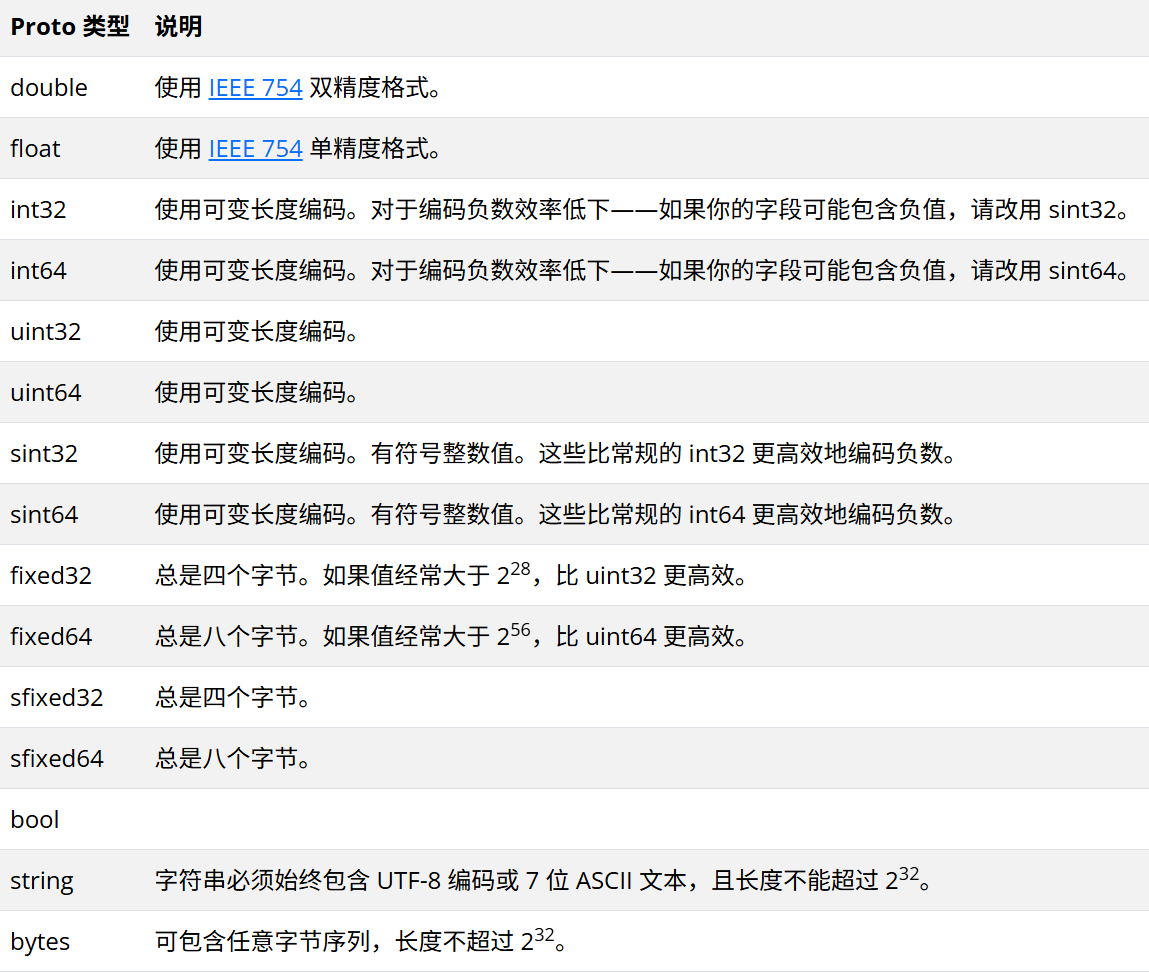
- 基础字段类型
- 注释标明了字段对应C#的类型,以及一些区别。
- 变长编码:会根据数字的大小,使用对应的字节数来存储,比如数字1就用一个字节存储,数字300用两个字节存储。这是Protobuf帮助我们优化的部分,我们无需过多关心,无非是内部序列化和反序列化时的方式不同。
- bytes:这个不是对应C#的byte数组,而是Protobuf提供的
BytesString类。
message FieldTypes {
//浮点数
float testFloat = 1; // C# - float
double testDouble = 2; // C# - double
//变长编码
int32 testInt32 = 3; // C# - int 它不太适用于来表示负数,请使用sint32
int64 testInt64 = 4; // C# - long 它不太适用于来表示负数,请使用sint64
sint32 testSInt32 = 5; // C# - int 适用于来表示负数的整数
sint64 testSInt64 = 6; // C# - long 适用于来表示负数的整数
uint32 testUInt = 7; // C# - uint 无符号变长的编码
uint64 testULong = 8; // C# - ulong 无符号变长的编码
//固定字节数的类型
fixed32 testFixed32 = 9; // C# - uint 表示大于2的28次方的数时,比uint32更有效,始终是4个字节
fixed64 testFixed64 = 10; // C# - ulong 表示大于2的56次方的数时,比uint64更有效,始终是8个字节
sfixed32 testSFixed32 = 11; // C# - int 始终4个字节
sfixed64 testSFixed64 = 12; // C# - long 始终8个字节
// 其他类型
bool testBool = 13; // C# - bool
string testStr = 14; // C# - string
bytes testBytes = 15; // C# - BytesString 字节字符串
}
- 特殊标识
- 一共有四个标识:
required、optional、repeated、map。需要注意的是required已从proto3中移除,所以请勿使用。
- 一共有四个标识:
message FieldCardinality {
required float testFloat = 1; //required:必须赋值的字段,proto2使用
optional double testDouble = 2; //optional:可以不赋值的字段
repeated int32 listInt = 3; // repeated:可重复字段,C#里是RepeatedField,类似List
map<int32, string> testMap = 4; // map:键值对字段,C#里是MapField,类似Dictionary
}
- 枚举
- 枚举变量声明以分号结尾。
- 枚举定义的第一个枚举值一定为0,命名最好带上
UNSPECIFIED或者UNKNOWN之类的。这是因为枚举默认值是第一个定义的枚举值,它必须为0。
enum TestEnum{
UNKNOWN = 0; // 枚举第一个值一定为0
Player = 1;
BOSS = 2;
}
-
默认值
- string:空字符串
- bytes:空字节
- bool:false
- 数值:0
- 枚举:0
- message:取决于语言,在C#里为null
-
嵌套
在message中允许嵌套,比如你可以在message里再声明一个message,或者再声明一个enum。
- 保留字段
如果修改了协议内容,删除了一些字段,为了避免更新时重新使用已经删除的编号,建议使用reserved关键字来保留字段,表示这些内容不再使用。这样可以避免版本不匹配时出现结构不统一、解析错误的问题。
可以使用编号或者变量名表示不再使用的内容。
// 方式一
reserved 3, 5, 9 to 11; // 3、5、9、10、11的编号都无法使用
// 方式二
reserved "foo", "bar"; // foo和bar变量的编号无法使用
- 导入定义(包)
- 可以通过
import导入另一个proto文件,
- 可以通过
import "proto_path";
4、Protobuf协议生成
(1)生成C#脚本的步骤
- 在protoc.exe所在文件夹中打开cmd窗口。
- 输入转换命令:
protoc.exe -I=配置路径 --csharp_out=输出路径 配置文件名。如果没有提示错误信息则生成完毕。 - 注意:路径不要有中文和特殊符号,避免生成失败。
(2)生成C#脚本的工具
手动敲命令比较麻烦,因此可以将这个过程制作成一个编辑器工具。这里需要用到C#的Process类,这个类用于控制进程,比如进程的启动和关闭等等。
public class ProtobufTool
{
// 协议配置文件路径
private static string PROTO_PATH = "你的proto配置文件路径";
// protoc.exe路径
private static string PROTOC_EXE_PATH = "你的protoc.exe路径";
// C#文件路径
private static string CSHARP_PATH = "你的C#脚本路径";
[MenuItem("ProtobufTool/生成C#代码")]
private static void GenerateCSharp()
{
// 获取配置文件夹信息
DirectoryInfo directoryInfo = Directory.CreateDirectory(PROTO_PATH);
FileInfo[] files = directoryInfo.GetFiles();
// 遍历每个文件
foreach (FileInfo file in files)
{
// 只处理proto配置文件
if (file.Extension == ".proto")
{
// 使用Process执行命令
Process cmd = new Process();
cmd.StartInfo.FileName = PROTOC_EXE_PATH; // 编译器路径
cmd.StartInfo.Arguments = $"-I={PROTO_PATH} --csharp_out={CSHARP_PATH} {file.Name}"; // 命令参数
cmd.Start();
UnityEngine.Debug.Log($"{file.Name} 生成完成");
}
}
}
}
5、Protobuf协议使用
我们以下面这个配置内容为例,使用上节做好的工具生成C#脚本后,就可以开始使用了。
syntax = "proto3";
package GameTest;
message TestMsg {
message TestMsg2 {
double testDouble = 1;
}
float testFloat = 1; // float
sint32 testInt = 2; // int
sint64 testLong = 3; // long
bool testBool = 4; // bool
string testStr = 5; // string
repeated int32 listInt = 6; // RepeatedField
map<int32, string> testMap = 7; // MapField
TestMsg2 testMsg2 = 8; // TestMsg2
}
- 序列化:
FileStream+WriteTo。- 这里创建消息内部声明的消息时,需要通过
.Types才可访问。
- 这里创建消息内部声明的消息时,需要通过
// 创建类对象
TestMsg msg = new TestMsg();
msg.TestFloat = 3.5f;
msg.TestInt = 4;
msg.TestLong = 123;
msg.TestBool = true;
msg.TestStr = "Hello Protobuf";
msg.ListInt.Add(1);
msg.TestMap.Add(1, "cat");
msg.TestMsg2 = new TestMsg.Types.TestMsg2();
msg.TestMsg2.TestDouble = 2.2;
// 将类对象序列化并写入到文件
using (FileStream fs = File.Create(Application.persistentDataPath + "/test.dat"))
{
msg.WriteTo(fs);
}
- 反序列化:
FileStream+Parser.ParseFrom。
// 从文件中读取数据并反序列化成类对象
using (FileStream fs = File.OpenRead(Application.persistentDataPath + "/test.dat"))
{
TestMsg msg2 = TestMsg.Parser.ParseFrom(fs);
}
- 获取序列化后的字节数组:
MemoryStream+WriteTo或者直接使用ToByteArray。- 通过内存流的
ToArray方法即可获取字节数组。
- 通过内存流的
// 将类对象序列化成字节数组
// 方式一:MemoryStream + WriteTo
using (MemoryStream ms = new MemoryStream())
{
msg.WriteTo(ms);
byte[] bytes = ms.ToArray();
}
// 方式二:ToByteArray
byte[] bytes2 = msg.ToByteArray();
- 从字节数组反序列化:
MemoryStream+Parser.ParseFrom或者直接使用Parser.ParseFrom的另一个重载。
// 从字节数组中反序列化成类对象
// 方式一:MemoryStream + Parser.ParseFrom
using (MemoryStream ms = new MemoryStream(bytes))
{
TestMsg msg3 = TestMsg.Parser.ParseFrom(ms);
}
// 方式二:Parser.ParseFrom另一个重载
TestMsg msg4 = TestMsg.Parser.ParseFrom(bytes);
总结:
- 写入文件使用
FileStream,获取字节数组使用MemoryStream。 - 序列化使用
WriteTo,这是IMessage的拓展方法。 - 反序列化使用
Parser.ParseFrom,这是MessageParser<T>的拓展方法。 - 使用字节数组时,可以直接使用
ToByteArray序列化,使用Parser.ParseFrom的重载方法反序列化。
6、实践
将上面这个Protobuf的序列化和反序列化封装成一个工具,方便后续使用。
- 序列化成字节数组时,直接调用
ToByteArray即可。 - 反序列化字节数组时,由于不知道具体的消息对象,因此需要通过反射,先获取到
Parser静态成员属性返回的对象,再调用这个对象的ParserFrom方法反序列化后,返回消息对象。
public static class NetTool
{
/// <summary>
/// 获取Protobuf消息对象的序列化字节数组
/// </summary>
/// <param name="msg">消息对象</param>
/// <returns>字节数组</returns>
public static byte[] GetProtoBytes(IMessage msg)
{
return msg.ToByteArray();
}
/// <summary>
/// 反序列化字节数组为Protobuf的消息对象
/// </summary>
/// <typeparam name="T">消息类型</typeparam>
/// <param name="bytes">字节数组</param>
/// <returns>消息对象</returns>
public static T GetProtoMsg<T>(byte[] bytes) where T : class, IMessage
{
// 通过反射获取消息对象
Type msgType = typeof(T);
// 通过Parser静态成员属性获取MessageParser<T>对象
PropertyInfo parserInfo = msgType.GetProperty("Parser");
object parserObj = parserInfo.GetValue(null, null);
// 通过反射获取该对象的ParseFrom方法,且参数是byte[]的重载方法
Type parserType = parserObj.GetType();
MethodInfo parserFrom = parserType.GetMethod("ParseFrom", new Type[] { typeof(byte[]) });
// 调用parseFrom方法,将字节数组转成消息对象
object msg = parserFrom.Invoke(parserObj, new object[] { bytes });
return msg as T;
}
}
(四)大小端模式
1、概念
(1)大小端
- 大端模式:指数据的高字节保存在内存的低地址中,数据的低字节保存在内存的高地址中。这种存储模式类似于把数据当作字符串顺序处理,符合人类的阅读习惯。
- 小端模式:指数据的高字节保存在内存的高地址中,数据的低字节保存在内存的低地址中。
(2)举例:十六进制数据0x11223344
- 大端模式:
11 22 33 44
0 1 2 3
低地址——>高地址
- 小端模式:
44 33 22 11
0 1 2 3
低地址——>高地址
(3)为什么有大小端
大小端模式是计算机硬件的两种存储数据的方式,大小端模式也可以称为大小端字节序。
大端字节序对人类来说阅读起来更加方便,而小端字节序方便计算机处理,因为计算机是按顺序读取字节,且计算机先处理低位字节,这样效率更高。
因此,除了计算机内部处理时,比如操作系统,其他场合几乎都用大端字节序,比如网络传输和文件存储。不过具体的模式,还是需要根据硬件平台,开发语言来决定,不同的开发环境,采用的大小端模式也会不一致。
(4)如何处理大小端
对于我们来说,只有读取的时候才必须区分大小端字节序,其它情况都不用考虑。
TCP/IP协议规定了在网络上必须采用网络字节序(即大端模式),但具体的模式还是需要根据前后端设备和语言来决定。比如下面这两个例子:
- C#和Java/Erlang/AS3通讯需要进行大小端转换,因为C#是小端模式,Java/Erlang/AS3是大端模式。
- C#与C++通信不需要特殊处理,他们都是小端模式。
Protobuf已经帮助我们解决了大小端问题,即使前后端语言不统一,使用它也不用过多考虑字节序转换的问题。
(5)大小端转换
- 此计算机体系结构中存储数据的字节顺序
BitConverter.IsLittleEndian; // 是否是小端模式
- 大小端转换简单API
- 只支持3种类型,做了解即可。
IPAddress.HostToNetworkOrder(num)用于将主机字节序转换成网络字节序(即转换成大端)。IPAddress.NetworkToHostOrder(num)用于将网络字节序转换成主机字节序
// 本机字节序转网络字节序
int num = 99;
byte[] bytes = BitConverter.GetBytes(IPAddress.HostToNetworkOrder(num));
// 网络字节序转本机字节序
int num2 = BitConverter.ToInt32(bytes, 0);
num2 = IPAddress.NetworkToHostOrder(num2);
- 更通用的大小端转换方法
- 使用
Array.Reverse将字节数组反转即可。
- 使用
if (BitConverter.IsLittleEndian)
Array.Reverse(bytes);
(五)消息加密解密
1、概述
进行网路传输时,我们会把数据转换为字节数组以二进制的形式进行传输,理论上来说,如果有人截取篡改了消息,或者从前端发假消息给后端,就可能产生作弊行为,而消息的加密解密可以有效避免作弊行为的产生。
- 加密:采用一些方式对数据进行处理后,使数据从表面上看,已经不能表达出原有的意思。这样可以使数据更加安全,降低被篡改的可能性。
- 解密:通过对加密过的数据采用某些方法,去还原原有数据,从而获取目标数据。
2、一些名词
- 明文:待加密的报文(内容)
- 密文:加密后的报文(内容)
- 密钥:加密过程中或解密过程中输入的数据
- 算法:将明文和密钥相结合进行处理,生成密文的方法,叫加密算法。将密文和密钥相结合进行处理,生成明文的方法,叫解密算法。
3、了解加密解密算法的分类
(1)单向加密
将数据进行计算变成另一种固定长度的值,这种加密是不可逆的。
- 常用算法:MD5、SHA1、SHA256等。
- 用途:这种加密在网络传输中不会使用,主要用到其它功能当中,比如密码的单向加密。
(2)对称加密技术
使用同一个密钥,对数据镜像加密和解密(用密钥对明文加密,用密钥对密文解密)。
- 常用算法:DES、3DES、IDEA、AES等。
- 优点:计算量小,加密速度快、效率高。
- 缺点:如果知道了密钥和算法,就可以进行解密。
- 用途:网路通讯中可以使用对称加密技术,这个密钥可以是由后端下发的,每次建立通讯后都会变化的。
(3)非对称加密技术
在加密过程中,需要一对密钥,不公开的密钥称为私钥,公开的那一个密钥称为公钥,也可以称为公开密钥加密。从一对密钥中的任何一个密钥都不能计算出另一个密钥,使用一对密钥中的任何一个加密,只有另一个密钥才能解密。如果截获公钥加密数据,没有私钥也无法解密。
- 常用算法:RSA、DSA等。
- 优点:安全性高,即使获取到了公钥,没有私钥也无法进行解密。
- 缺点:算法复杂,加密速度较慢。
- 用途:对安全性要求较高的场景,并且可以接受较慢的加密速度的需求可以使用非对称加密技术,比如对接一些支付SDK时经常会看到平台提供的就是非对称加密技术。
4、总结
关于这些加密算法,由于内容庞大,且有很多第三方加密算法库可以使用,因此目前来说学习的优先级不高。我们只需了解内容,知道加密的意义即可,如果有需求再去学习对应算法。